はじめに #
演習:Ridge 回帰 では
ハイパーパラメータalphaの値は0.0と0.1の2通りで固定して Ridge 回帰を行った.
この演習では,交差検証(cross-validation: CV)によりハイパーパラメータチューニングを行う.
ここでは,KFoldを用いて CV を行い,alphaを変化させながら最適なalphaを探索する.
実は scikit-learn にはその処理を自動化した RidgeCV というクラスがあるが,
まずは自分である程度コードを書いて流れを理解した方が良い.
Jupyter Notebookでの演習を想定.下記のようにライブラリのインポートも必要. ここに出てくるグラフ出力例は Matplotlib > よく使う設定と保存 の設定も用いている.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures, StandardScaler
from sklearn.linear_model import Ridge
from sklearn.metrics import root_mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold演習1:k-fold の練習 #
演習:Ridge 回帰 では訓練データとテストデータを分けて生成して準備したが,普通はデータセットが一つあって,それを訓練データとテストデータに分割して回帰等を行う. データの分け方は色々あるが,ここでは以下の図のようなデータ分割を考える. テストデータは最後まで取っておき,訓練データをk分割する.
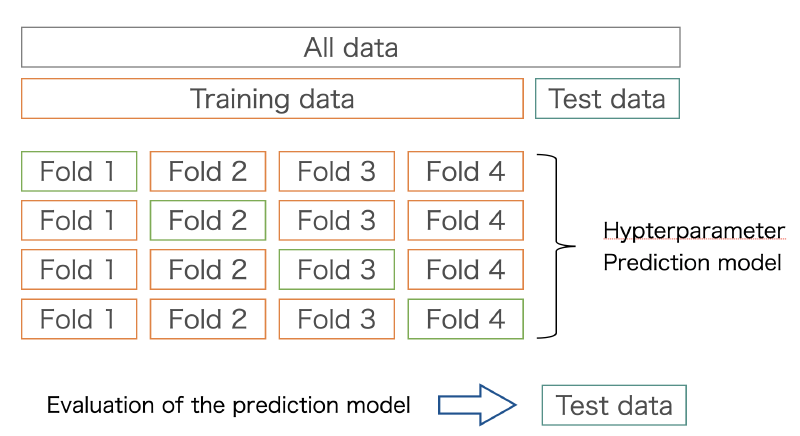
ここでは,下記サイトのExample(3.1.2.1.1. K-fold)を試して scikit-learn の KFoldの使う練習から始める.
https://scikit-learn.org/stable/modules/cross_validation.html#k-fold
インデックスが返ってくると思うので,どのようにインデックスを利用すれば良いか理解すること. 下記のコードも試して,動作を理解しておくこと.
shuffle=Trueにしておくと,テストのindexの選び方が順番通りではなくシャッフルされる.random_stateは seed.何か適当な数値を入れおけば再現性がとれる.
hogex = np.array(["a", "b", "c", "d", "e", "f", "g", "h"])
hogey = np.array([1, 2, 3, 4, 5, 6, 7, 8])
kf = KFold(n_splits=4, shuffle=True, random_state=None)
for i, (train_idx, valid_idx) in enumerate(kf.split(hogex), start=1):
print(f'loop: {i}')
print('train index :', train_idx)
print('validation index :', valid_idx)
print('train data :', hogex[train_idx], hogey[train_idx])
print('validation data :', hogex[valid_idx], hogey[valid_idx])
print()出力
loop: 1
train index : [2 3 4 5 6 7]
validation index : [0 1]
train data : ['c' 'd' 'e' 'f' 'g' 'h'] [3 4 5 6 7 8]
validation data : ['a' 'b'] [1 2]
loop: 2
train index : [0 1 2 4 5 6]
validation index : [3 7]
train data : ['a' 'b' 'c' 'e' 'f' 'g'] [1 2 3 5 6 7]
validation data : ['d' 'h'] [4 8]
loop: 3
train index : [0 1 3 5 6 7]
validation index : [2 4]
train data : ['a' 'b' 'd' 'f' 'g' 'h'] [1 2 4 6 7 8]
validation data : ['c' 'e'] [3 5]
loop: 4
train index : [0 1 2 3 4 7]
validation index : [5 6]
train data : ['a' 'b' 'c' 'd' 'e' 'h'] [1 2 3 4 5 8]
validation data : ['f' 'g'] [6 7]演習2:データの準備と分割 #
まずこれまでと同様にsin関数に関連するデータをいくつか準備する.
データ数はなんでも良いが,すぐに変えられるようにここではndataという変数を用いる.
データ数は自分で何度か変更してみて色々試してみること.
データが少ないと検証誤差のブレが大きくうまくいかないことが多いので, データを40点生成し,訓練データとテストデータに分ける. ここで分けるのは k-fold ではなく,最後まで取っておくためのテストデータ.
まずいつも通りデータを40点生成する.
ndata = 40
x_dense = np.linspace(0, 1, 100)
y_sin = np.sin(2 * np.pi * x_dense)
rng = np.random.default_rng() # 何か適当なseed値を入れておくと良い
x_all = ?????? # ndataを使ってデータ生成
y_all = ??????
noise = ?????? # ndataを使ってデータ生成
y_all = y_all + noisescikit-leaarn には train_test_split というデータをランダムに分割することができる関数があるので,それを利用する.train_test_split はデフォルトでshuffle=Trueになっている.
x_train, x_test, y_train, y_test = train_test_split(
x_all,
y_all,
test_size=0.2,
random_state=None,
)random_stateに何か適当な seed 値を入れておくと再現できる
test_size=0.2のように40データのうちの2割がテストになるように分割される.
いつも通りsin関数とともにプロットして,きちんとデータが分割されているか確認する.
fig, ax = plt.subplots(1, 1)
ax.plot(x_dense, y_sin, label=r'$\sin(2\pi x)$')
ax.plot(x_train, y_train, 'o', markeredgecolor='black', label='Training data')
ax.plot(x_test, y_test, 's', markeredgecolor='black', label='Test data')
ax.set_xlabel(r'$x$')
ax.set_ylabel(r'$y$')
ax.legend(loc='upper right')
演習3:CV によるハイパーパラメータチューニング #
これまで通り,計画行列を計算する関数を準備しておく.
def design_matrix(x, M):
pf = PolynomialFeatures(degree=M, include_bias=False)
dmat = ??????
return dmatalphaはnp.logspace(参考:np.logspace)を使って対数スケールで変化させる.
下記のn_alphasやalphasの範囲などは各自調整すること.
n_alphas = 100
alphas = np.logspace(-10, 3, n_alphas)上記alphasを for 文で回しながら,CV で RMSE を k 回計算して,その平均を求める.
この例での分割数は \(k = 4\) にするが,各自で調整してよい.
# ---------- settings
M = 9 # 多項式の次数
nsp = 4 # k分割の数
mean_rmse_train = [] # 各alphaの値における訓練データに対するRMSEの平均
mean_rmse_valid = [] # 各alphaの値における検証データに対するRMSEの平均
# ---------- loop for alpha
for alpha in alphas:
kf = KFold(n_splits=nsp, shuffle=True, random_state=None) # random_stateに何か適当なseed値を入れて確認するとよい
fold_rmse_train = [] # alphaごとに,CV中の訓練データに対するRMSEを格納するためのリスト
fold_rmse_valid = [] # alphaごとに,CV中の検証データに対するRMSEを格納するためのリスト
# ---------- k-loop
for train_idx, valid_idx in kf.split(x_train):
# ------ k分割の訓練データと検証データ
x_fold_train = x_train[train_idx] # x_trainを分割
x_fold_valid = x_train[valid_idx] # x_trainを分割
y_fold_train = y_train[train_idx] # y_trainを分割
y_fold_valid = y_train[valid_idx] # y_trainを分割
# ------ 計画行列の作成と標準化
phi = design_matrix(??????, M) # 計画行列作成
ss = StandardScaler()
phi_std = ?????? # 標準化
# ------ 検証データの計画行列と標準化
phi_valid = design_matrix(??????, M) # 検証データの計画行列作成
phi_valid_std = ?????? # 検証データはfitはしない。transformだけ
# ------ Ridge回帰
ridge = Ridge(alpha=alpha, fit_intercept=True)
ridge.fit(??????, ??????) # fit
y_fold_predict = ridge.predict(??????) # 訓練データに対する予測値
y_fold_valid_predict = ridge.predict(??????) # 検証データに対する予測値
# ------ RMSEの計算
fold_rmse_train.append(root_mean_squared_error(??????, ??????)) # 訓練
fold_rmse_valid.append(root_mean_squared_error(??????, ??????)) # 検証
# ---------- alphaごとのRMSEの平均と標準偏差を格納
fold_rmse_train = np.array(fold_rmse_train)
fold_rmse_valid = np.array(fold_rmse_valid)
mean_rmse_train.append(fold_rmse_train.mean()) # CVの平均値を格納
mean_rmse_valid.append(fold_rmse_valid.mean())訓練データ(x_fold_trainなどのこと)と検証データに対する誤差を
横軸alpha,縦軸 RMSE のグラフでプロットする.
40データでも少ないくらいなので,検証誤差のブレが大きく,うまくいかない場合はデータ数などを調整すること.
fig, ax = plt.subplots(1, 1)
ax.plot(alphas, mean_rmse_train, label='Training')
ax.plot(alphas, mean_rmse_valid, label='Validation')
ax.set_xscale('log') # 横軸を対数スケールにする
ax.set_ylim(0, 1) # 縦軸の範囲を指定
ax.set_xlabel(r'$\alpha$')
ax.set_ylabel('RMSE')
ax.legend()
検証誤差が最小になるalphaをalpha_optとして求めておく.
np.argmin(最小となるインデックスを返すメソッド.わからない人は調べること)を用いる.
alpha_opt = alphas[np.argmin(mean_rmse_valid)]
alpha_opt # jupyterで出力用この例では0.003053855508833419が出力された.
演習4:最適化したハイパーパラメータを用いた Ridge 回帰 #
ハイパーパラメータチューニングができたので,上で求めたalpha_optと全ての訓練データを用いて改めて Ridge 回帰を行う.
比較のために,ここでもalpha=0.0の最小二乗法の計算も行う.
あとは 演習:Ridge 回帰 のときと同じことを行えばよい.
計画行列 #
# ---------- 計画行列の計算
phi = design_matrix(??????, M) # 計画行列作成
phi_test = design_matrix(??????, M) # テストデータの計画行列作成
phi_dense = design_matrix(??????, M) # x_denseの計画行列作成
# ---------- 標準化
ss = StandardScaler()
phi_std = ss.?????? # 標準化
phi_test_std = ss.?????? # テストデータの標準化.fitはしない
phi_dense_std = ss.?????? # x_denseの標準化.fitはしないalpha=0.0
#
ridge0 = Ridge(alpha=0, fit_intercept=True)
ridge0.fit(??????, ??????) # fit
y0_dense_predict = ridge0.predict(??????) # x_denseに対する予測値fig, ax = plt.subplots(1, 1)
ax.plot(x_dense, y_sin, label=r'$\sin(2\pi x)$')
ax.plot(x_train, y_train, 'o', markeredgecolor='black', label='Training data')
ax.plot(x_test, y_test, 's', markeredgecolor='black', label='Test data')
ax.plot(x_dense, y0_dense_predict, label='Prediction')
ax.set_ylim(-1.5, 1.5) # 過学習するのでyの描画範囲を設定しておいた方がいい
ax.set_xlabel(r'$x$')
ax.set_ylabel(r'$y$')
ax.legend(loc='upper right')
データ数が増えても,訓練データがない端の方では大きく外れているのがわかる.
alpha_opt
#
ridge1 = Ridge(alpha=alpha_opt, fit_intercept=True)
ridge1.fit(??????, ??????) # fit
y1_dense_predict = ridge1.predict(??????) # x_denseに対する予測値fig, ax = plt.subplots(1, 1)
ax.plot(x_dense, y_sin, label=r'$\sin(2\pi x)$')
ax.plot(x_train, y_train, 'o', markeredgecolor='black', label='Training data')
ax.plot(x_test, y_test, 's', markeredgecolor='black', label='Test data')
ax.plot(x_dense, y1_dense_predict, label='Prediction')
ax.set_ylim(-1.5, 1.5) # 過学習するのでyの描画範囲を設定しておいた方がいい
ax.set_xlabel(r'$x$')
ax.set_ylabel(r'$y$')
ax.legend(loc='upper right')
最小二乗法よりうまく回帰できている.
誤差の評価 #
演習:Ridge 回帰 のときと全く同様に評価できるので,ここでは結果の例だけ載せておく.各自でやってみること.
Parity plot #
alpha=0.0

alpha_opt

RMSE #
alpha=0.0
Training: RMSE = 0.08028158915814174
Test: RMSE = 0.6539752273916258alpha_opt
Training: RMSE = 0.08888866230477017
Test: RMSE = 0.08870881375600688